
Configuring API details via environment variables
Making code and configuration reusable
Let's say we have three environments - development, test and production - and each of them uses a different address for an external endpoint. The endpoint's functionality is the same but the provider of this API also has several environments matching yours.
What we want to achieve is twofold:
- Ensuring that the code does not need changes when you deploy it in each of your environments
- Making configuration artefacts, such as files with details of where the external APIs are, independent of a particular environment that executes your code
In this article, we will see how it can be done.
Python code
In the snippet below, we have an outgoing REST connection called CRM which the Python code uses to access an external system.
Zato knows that CRM maps to a specific set of parameters, like host, port, URL path or security credentials to invoke the remote endpoint with.
# -*- coding: utf-8 -*-
# Zato
from zato.server.service import Service
class GetUserDetails(Service):
""" Returns details of a user by the person's name.
"""
name = 'api.user.get-details'
def handle(self):
# Name of the connection to use
conn_name = 'CRM'
# Get a connection object
conn = self.out.rest[conn_name].conn
# Create a request
request = {
"user_id": 123
}
# Invoke the remote endpoint
response = conn.get(self.cid, request)
# Skip the rest of the implementation
pass
The above fulfills the first requirement - our code only ever uses the name CRM and it never has to actually consider what lies behind it, what CRM in reality points to.
All it cares about is that there is some CRM that gives it the required user data - if the connection details to the CRM change, the code will continue to work uninterrupted.
This is already good but we still have the other requirement - that CRM point to different external endpoints depending on which of your environment your code currently runs in.
This is where environment variables come into play. They let you move the details of a configuration to another layer - instead of keeping them along with your code, they can be specified for each execution environment separately. In this way, neither code nor configuration need any modifications - only environment variables change.
Zato Dashboard, enmasse CLI and Docker
When Dashboard is used for configuration, enter environment variables prefixed with a dollar sign "$" instead of an actual value. Zato will understand that the real value is to be read from the server's environment.
For instance, if the CRM is available under the address of https://example.net, create a variable called CRM_ADDRESS with the value of "https://example.net", store it in your \~/.bashrc or a similar file, source this file or log in to a new Linux shell, and then log in to Dashboard to fill out the corresponding form as here.
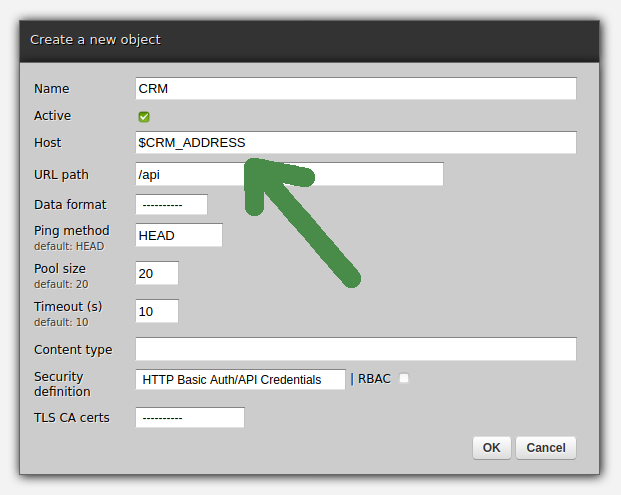
Once you click OK, restart your Zato servers for the changes to take effect. From now on, each time the CRM connection is used by any service, its address will be read from what $CRM_ADDRESS reads.
In this way, you can assign different values to as many environment variables as needed and Zato will read them when the server starts or when you edit a given connection's definition in Dashboard or via enmasse.
If you use enmasse for DevOps automation, the same can be done in your YAML configuration files, for instance:
Note that the same can be used if you start Zato servers in Docker containers.
For instance, in one environment you can start it as such:
sudo docker run \
--env CRM_ADDRESS=https://example.net \
--publish 17010:17010 \
--detach \
mycompany/myrepo
In another environment, the address may be different:
sudo docker run \
--env CRM_ADDRESS=https://example.com \
--publish 17010:17010 \
--detach \
mycompany/myrepo
Finally, keep in mind that environment variables can be used in place of any string or integer values, no matter what kind of a connection type we consider, which means that parameters such as pool sizes, usernames, timeouts or options of a similar nature can be always specified using variables specific to each environment without a need for maintaining config files for each environment independently.