In systems-to-systems integrations, there comes an inevitable time when we have to employ some kind of a web scraping tool to integrate with a particular application. Despite its not being our first choice, it is good to know what to use at such a time - in this article, I provide a gentle introduction to my favorite tool of this kind, called Playwright, followed by sample Python code that integrates it with an API service.

Naturally, in the context of backend integrations, web scraping should be avoided and, generally, it should be considered the last resort. The basic issue here is that while the UI term contains the "interface" part, it is not really the "Application Programming" Interface that we would like to have.
It is not that the UI cannot be programmed against. After all, a web browser does just that, it takes a web page and renders it as expected. Same goes for desktop or mobile applications. Also, anyone integrating with mainframe computers will recognize that this is basically what 3270 can be used for too.
Rather, the fundamental issue is that web scraping goes against the principles of separation of layers and roles across frontend, middleware and backend, which in turn means that authors of resources (e.g. HTML pages) do not really expect for many people to access them in automated ways.
Perhaps they actually should expect it, and web pages should finally start to resemble genuine knowledge graphs, easy to access by humans, be it manually or through automation tools, but the reality today is that it is not the case and, in comparison with backend systems, the whole of the web scraping space is relatively brittle, which is why we shun this approach in integrations.
Yet, another part of reality, particularly in enterprise integrations, is that people may be sometimes given access to a frontend application on an internal network and that is it. No API, no REST, no JSON, no POST data, no real data formats, and one is simply supposed to fill out forms as part of a business process.
Typically, such a situation will result in an integration gap. There will be fully automated parts in the business process preceding this gap, with multiple systems coordinated towards a specific goal and there will be subsequent steps in the process, also fully automated.
Or you may be given access only to a specific frontend and only through VPN via a single remote Windows desktop. Getting access to a REST API may take months or may be never realized because of some high level licensing issues. This is not uncommon in the real life.
Such a gap can be a jarring and sore point, truly ruining the whole, otherwise fluid, integration process. This creates a tension and to resolve the tension, we can, should all the attempts to find a real API fail, finally resort to web scraping.
It is mostly in this context that I am looking at Playwright below - the tool is good and it has many other uses that go beyond the scope of this text, and it is well worth knowing it, for instance for frontend testing of your backend systems, but, when we deal with API integrations, we should not overdo with web scraping.
Needless to say, if web scraping is what you do primarily, your perspective will be somewhat different - you will not need any explanation of why it is needed or when, and you may be only looking for a way to enclose up your web scraping code in API services. This article will explain that too.
The nice part of Playwright is that we can use it to visually prepare a draft of Python code that will scrape a given resource. That is, instead of programming it in Python, we go to an address, fill out a form, click buttons and otherwise use everything as usually and Playwright generates for us code that will be later used in integrations.
That code will require a bit of clean-up work, which I will talk about below, but overall it works very nicely and is certainly useful. The result is not one of these do-not-touch auto-generated pieces of code that are better left to their own.
While there are better ways to integrate with Jira, I chose that application as an example of Playwright's usage simply because I cannot show you any internal application in a public blog post.
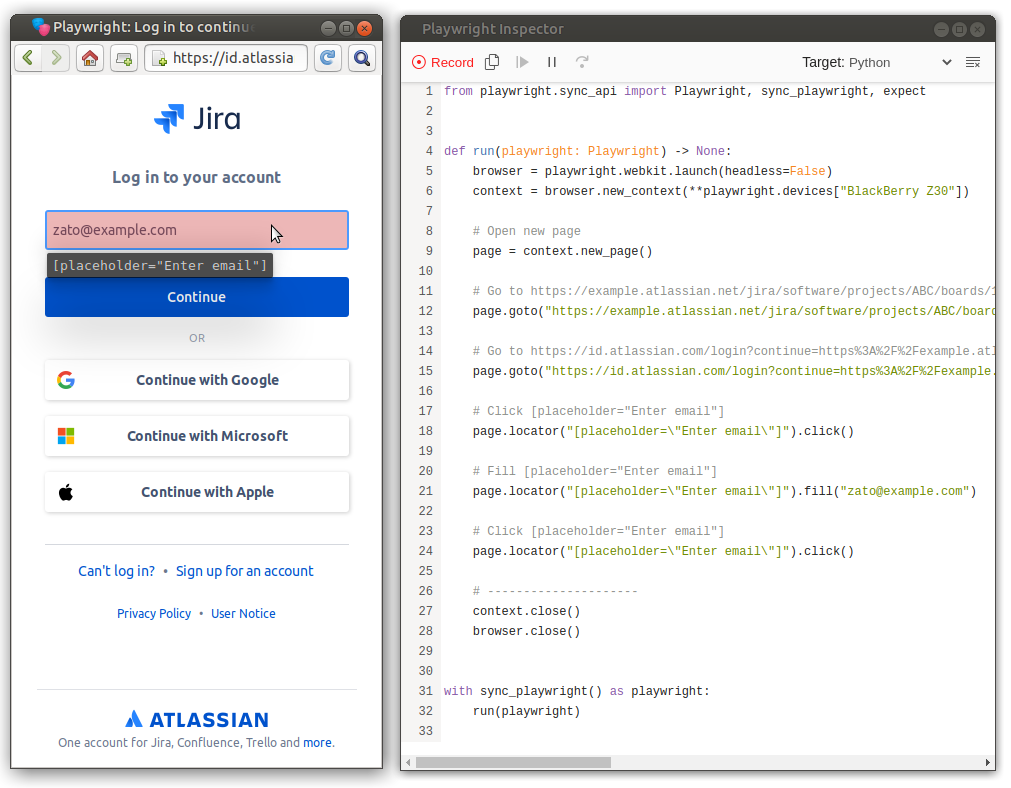
Below, there are two windows. One is Playwright's emulating a Blackberry device to open a resource. I was clicking around, I provided an email address and then I clicked the same email field once more. To the right, based on my actions, we can find the generated Python code, which I consider quite good and readable.
The Playwright Inspector, the tool that gave us the code, will keep recording all of our actions until we click the "Record" button which then allows us to click the button next to "Record" which is "Copy code to clipboard". We can then save the code to a separate file and run it on demand, automatically.
But first, we will need to install Playwright.
The tools is written in TypeScript and can be installed using npx, which in turn is part of NodeJS.
Afterwards, the "playwright install" call is needed as well because that will potentially install runtime dependencies, such as Chrome libraries.
Finally, we install Playwright using pip as well because we want to access with Python. Note that if you are installing Playwright under Zato, the "/path/to/pip" will be typically "/opt/zato/code/bin/pip".
We can now start it as below. I am using BlackBerry as an example of what Playwright is capable of. Also, it is usually more convenient to use a mobile version of a site when the main window and Inspector are opened side by side, but you may prefer to use Chrome, Firefox or anything else.
That is practically everything as using Playwright to generate code in our context goes. Open the tool, fill out forms, copy code to a Python module, done.
What is still needed, though, is cleaning up the resulting code and embedding it in an API integration process.
After you keep using Playwright for a while with longer forms and pages, you will note that the generated code tends to accumulate parts that repeat.
For instance, in the module below, which I already cleaned up, the same "[placeholder=\"Enter email\"]" reference to the email field is used twice, even if a programmer developing this could would prefer to introduce a variable for that.
There is not a good answer to the question of what to do about it. On the one hand, obviously, being programmers we would prefer not to repeat that kind of details. On the other hand, if we clean up the code too much, this may result in too much of a maintenance burden because we need to keep it mind that we do not really want to invest to much in web scraping and, should there be a need to repeat the whole process, we do not want to end up with Playwright's code auto-generated from scratch once more, without any of our clean-up.
A good compromise position is to at least extract any kind of credentials from the code to environment variables or a similar place and to remove some of the code comments that Playwright generates. The result as below is what it should like at the end. Not too much effort without leaving the whole code as it was originally either.
Save the code below as "play1.py" as this is what the API service below will use.
# -*- coding: utf-8 -*-
# stdlib
import os
# Playwright
from playwright.sync_api import Playwright, sync_playwright
class Config:
Email = os.environ.get('APP_EMAIL', 'zato@example.com')
Password = os.environ.get('APP_PASSWORD', '')
Headless = bool(os.environ.get('APP_HEADLESS', False))
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=Config.Headless) # type: ignore
context = browser.new_context()
# Open new page
page = context.new_page()
# Open project boards
page.goto("https://example.atlassian.net/jira/software/projects/ABC/boards/1")
page.goto("https://id.atlassian.com/login?continue=https%3A%2F%2Fexample.atlassian.net%2Flogin%3FredirectCount%3D1%26dest-url%3D%252Fjira%252Fsoftware%252Fprojects%252FABC%252Fboards%252F1%26application%3Djira")
# Fill out the email
page.locator("[placeholder=\"Enter email\"]").click()
page.locator("[placeholder=\"Enter email\"]").fill(Config.Email)
# Click #login-submit
page.locator("#login-submit").click()
with sync_playwright() as playwright:
run(playwright)
We have the generated code so the first thing to do with it is to run it from command line. This will result in a new Chrome window's accessing Jira - it is Chrome, not Blackberry, because that is the default for Playwright.
The window will close soon enough but this is fine, that code only demonstrates a principle, it is not a full integration task.
It is also useful that we can run the same Python module from our IDE, giving us the ability to step through the code line by line, observing what changes when and why.
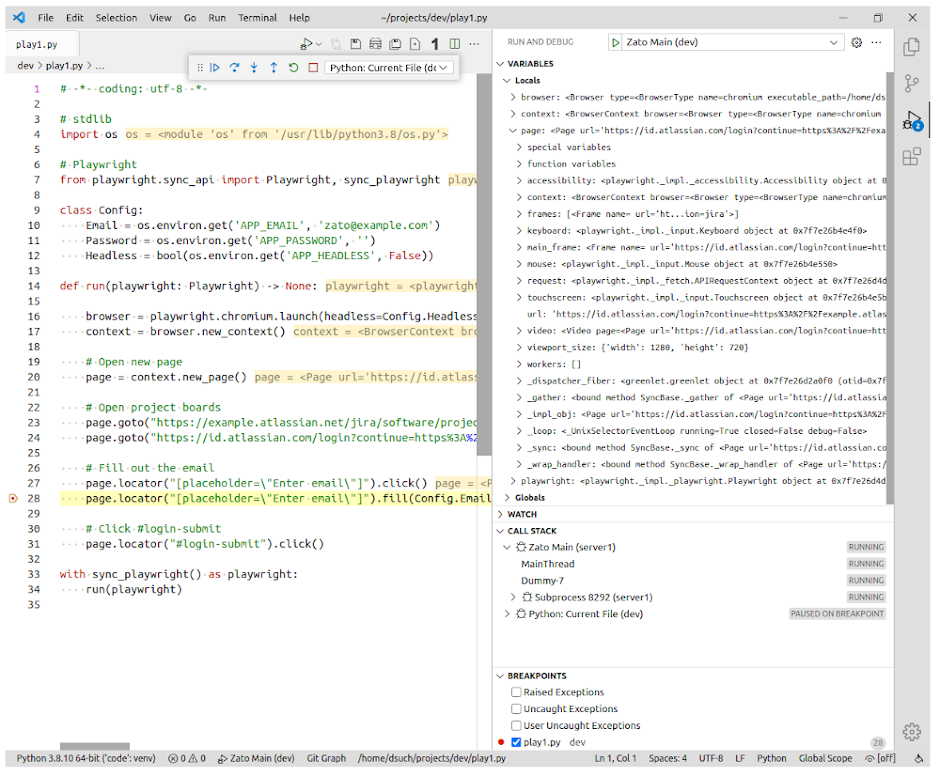
Finally, we are ready to invoke the standalone module from an API service, as in the following code that we are also going to make available as a REST channel.
A couple of notes about the Python service below:
Other than that, this is a straightforward Zato service - it receives input, carries out its work and a reply is returned to the caller (here, empty).
# -*- coding: utf-8 -*-
# stdlib
from dataclasses import dataclass
# Zato
from zato.server.service import Model, Service
# ###########################################################################
@dataclass(init=False)
class WebScrapingDemoRequest(Model):
email: str
password: str
# ###########################################################################
class WebScrapingDemo(Service):
name = 'demo.web-scraping'
class SimpleIO:
input = WebScrapingDemoRequest
def handle(self):
# Path to a Python installation that Playwright was installed under
py_path = '/path/to/python'
# Path to a Playwright module with code to invoke
playwright_path = '/path/to/the-playwright-module.py'
# This is a template script that we will invoke in a subprocess
command_template = """
APP_EMAIL={app_email} APP_PASSWORD={app_password} APP_HEADLESS=True {py_path} {playwright_path}
"""
# This is our input data
input = self.request.input # type: WebScrapingDemoRequest
# Extract credentials from the input ..
email = input.email
password = input.password
# .. build the full command, taking all the config into account ..
command = command_template.format(
app_email = email,
app_password = password,
py_path = py_path,
playwright_path = playwright_path,
)
# .. invoke the command in a subprocess ..
result = self.commands.invoke(command)
# .. if it was not a success, log the details received ..
if not result.is_ok:
self.logger.info('Exit code -> %s', result.exit_code)
self.logger.info('Stderr -> %s', result.stderr)
self.logger.info('Stdout -> %s', result.stdout)
# ###########################################################################
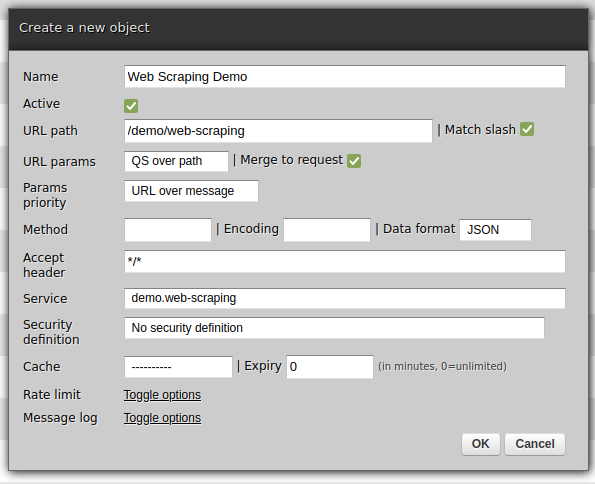
Now, the REST channel:
The last thing to do is to invoke the service - I am using curl from the command line below but it could very well be Postman or a similar option.
There will be no Chrome window this time around because we run Playwright in the headless mode. There will be no output from curl either because we do not return anything from the service but in server logs we will find details such as below.
We can learn from the log that the command took close to 4 seconds to complete, that the exit code was 0 (indicating success) and that is no stdout or stderr at all.
INFO - Command `
APP_EMAIL=hello@example.com APP_PASSWORD=abc APP_HEADLESS=True
/path/to/python
/path/to/the-playwright-module.py
` completed in 0:00:03.844157,
exit_code -> 0; len-out=0 (0 Bytes); len-err=0 (0 Bytes);
cid -> zcmdc5422816b2c6ff9f10742134
We are now ready to continue to work on it - for instance, you will notice that the password is visible in logs and this should not be allowed.
But, all such works are extra in comparison with the main theme - we have Playwright, which is a a tool that allows us to quickly integrate with frontend applications and we can automate it through API services. Just as expected.
➤ Python API integration tutorials
➤ What is an integration platform?
➤ Python Integration platform as a Service (iPaaS)
➤ What is an Enterprise Service Bus (ESB)? What is SOA?
➤ Open-source iPaaS in Python
