Zato is a Python-based middleware and backend platform designed for integrating and building server-side systems.
The platform belongs to a broader family of solutions that, depending on one's background, will be known under the name of an integration layer, integration platform, service-oriented platform, enterprise service bus, API server, message bus, message queue, message broker, orchestration engine or similar.
Zato, as multi-purpose software, can fulfill all of the roles listed above and it is specifically designed with systems integrations and backend, API-only solutions in mind.
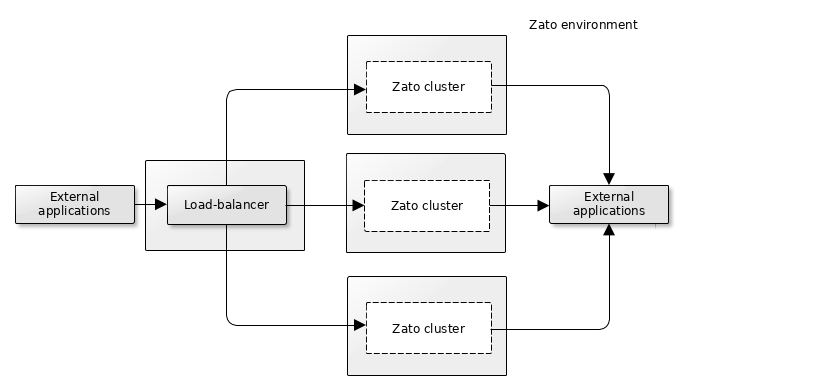
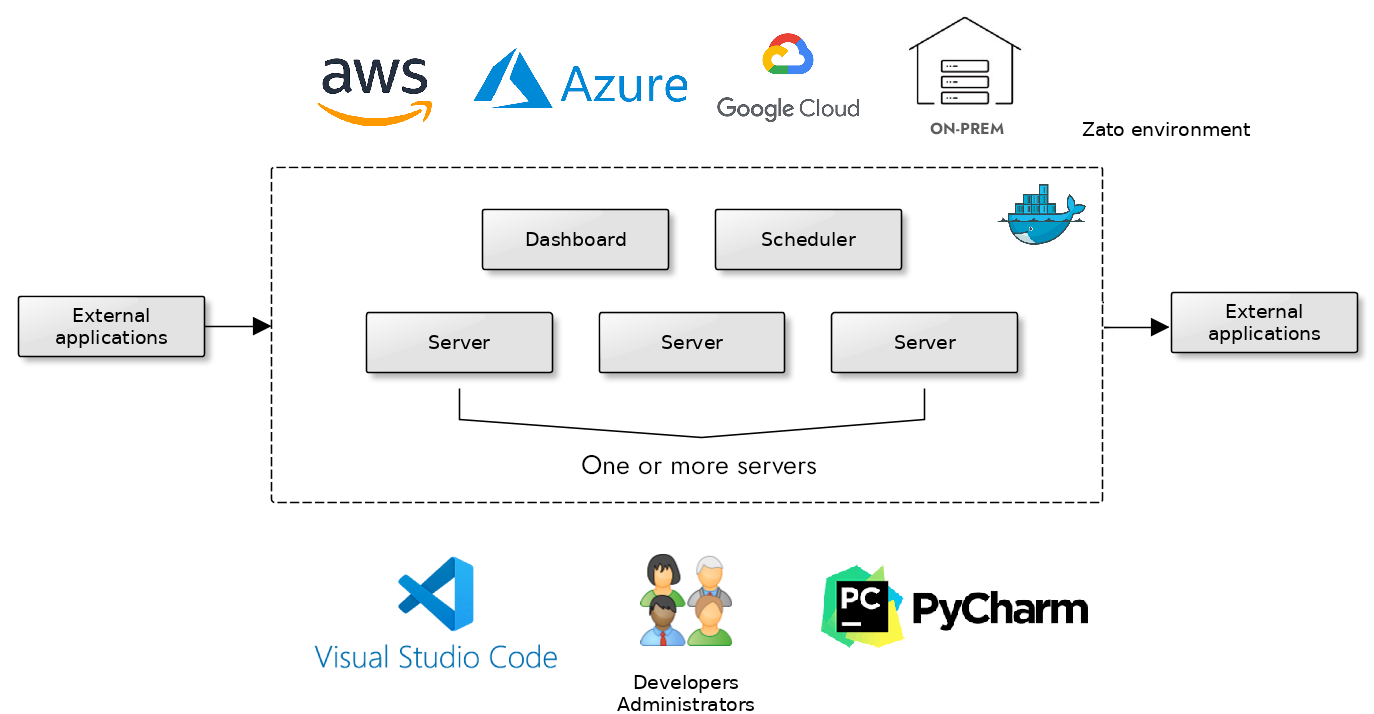
At its core, each Zato environment is composed of one or more clusters. Clusters are lightweight compositional units of deployment consisting of one or more servers, a scheduler, a web-based dashboard for administration, and a load-balancer. Each of the components may be potentially running in its own instance, VM or container.
Production clusters will run in any Linux environment, no matter if it is a cloud one or on premises, under containers or without. Development and test clusters will run under Docker or Vagrant on any OS.
To ensure utmost productivity, tight integration with the most popular IDEs is provided out-of-the box, including deploy-on-save and remote debugging.
The built-in load-balancer, based on HAProxy, can be replaced by an external one, be it a separate process, a cloud-based load-balancer (e.g. ALB in AWS) or a dedicated appliance.
One of the fundamental concepts in Zato is hot-deployment - when you deploy a new version of a service to one server, all other servers in the cluster will synchronize that information and only that one service will be reconfigured and changed, there is no need to restart entire servers in such a case. Hot-deployment of new functionality is counted in milliseconds.
Hot-deployment is essential in integrations that make use of long-running persistent connections, such as from IoT devices, that would otherwise require for all the connected clients to reconnect after each server restart.
Hot-deployment is also important during development - you can configure your IDE to hot-deploy code to a cluster each time your code is saved. Or you can deploy newest code to the whole cluster each time "git pull" runs in a special directory that a file listener monitors for changes. In short, hot-deployment lets you avoid unnecessary downtime.
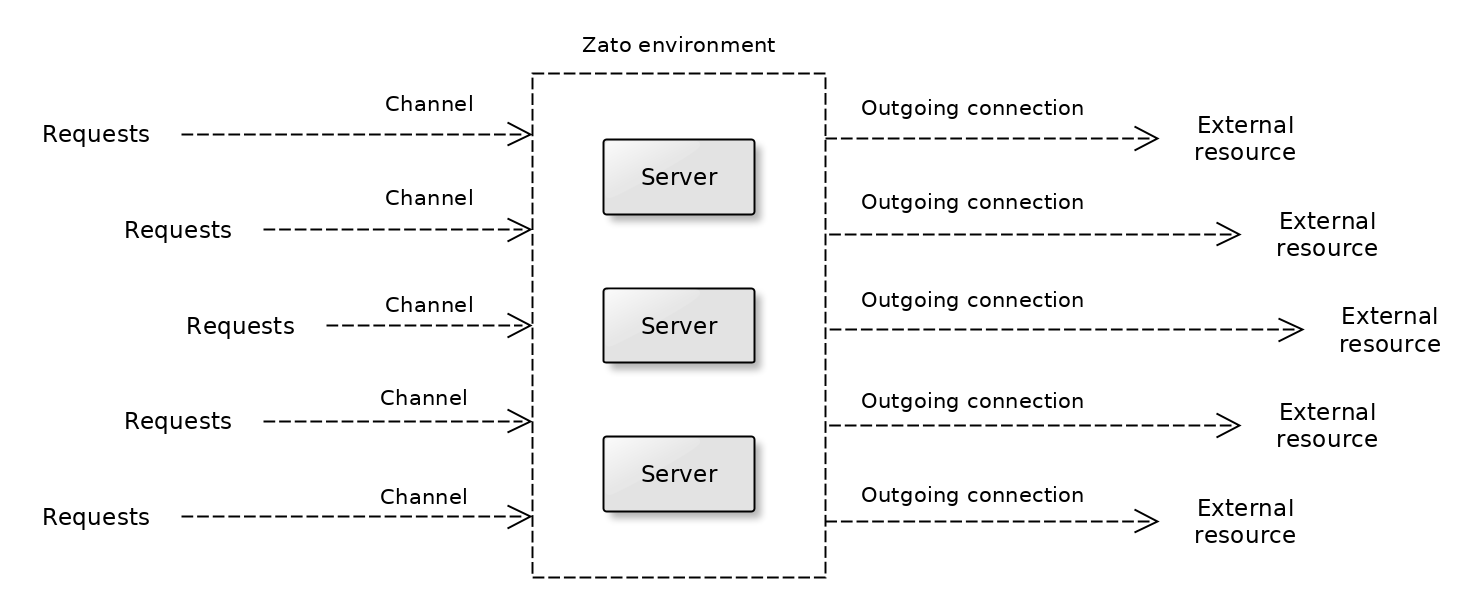
Servers in each cluster always execute the same code and they always run in active-active mode. That is, there is no notion of a standby server within the boundaries of a single cluster. Rather, a separate standby cluster is created if needed.
Servers are always members of a cluster. Even if there is a single server in an environment, it always belongs to a cluster whose sole member it is.
Requests are accepted by channels and external resources are accessed through outgoing connections.
Servers need to be able to communicate with each other in order to keep their internal configuration and state of the cluster in sync, which means that they need direct TCP communication paths between each member of the cluster.
Each server executes business services written in Python - to learn more about what a Zato service is, read the high-level overview.
Services can be independent of a particular data format of channel, e.g. the same service can use REST, JSON-RPC, file transfer, WebSockets, IBM MQ, AMQP or other communication means.
Services require little RAM in runtime and little time to deploy. A typical service will consume roughly 1 MB of RAM when idle and will require less than 1 ms to deploy. Hence, even a server with 500 or 1000 services will require little computing resources to operate, implying low electricity and cooling costs as well as low CO2 emission and environmental impact.
Services can accept requests through a range of channels. They can invoke other systems through one of many outgoing connection types, such as REST, AMQP, Cloud, HL7, Kafka, MongoDB and various others typically used in backend environments.
Each server acts as a cache with a Python API for your services. The contents of the cache is also accessible through a cluster's dashboard.
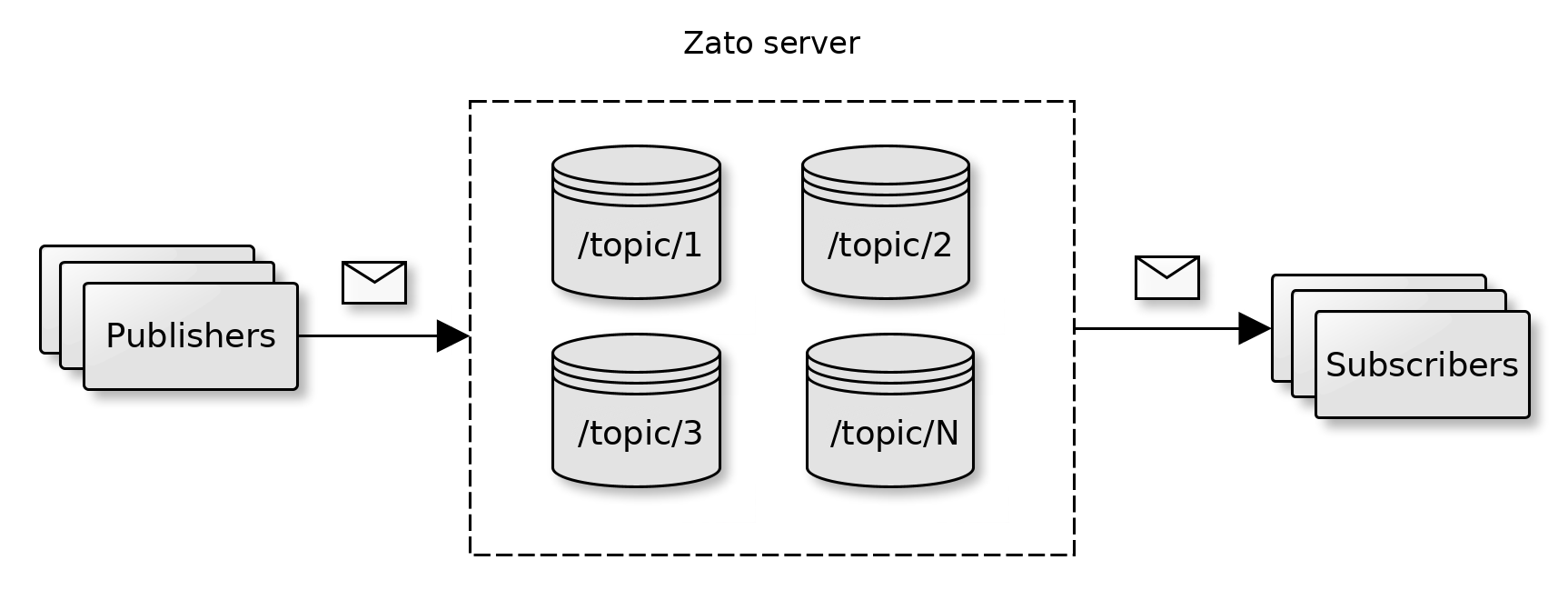
Each server can act as a publish/subscribe message broker offering topics and queues to asynchronous publishers and subscribers. Messages can be retained in persistent storage to ensure guaranteed delivery.
The message broker is multi-protocol and can be used by Python, REST or WebSockets-based clients. Each cluster's Dashboard acts as a GUI to manage the topics, queues and endpoints participating in pub/sub integrations.
Each cluster comes with a highly configurable scheduler whose jobs can be triggered in predefined intervals.
Each job invokes a service running in the cluster's servers. Because services are protocol independent, it means that the same service can be made available to external API clients and, internally, to the scheduler as well.
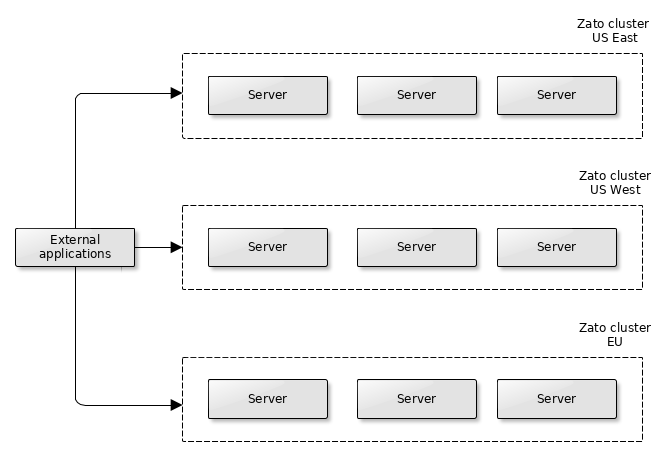
There are no limits as to how many clusters can be used in a single environment and each server can use multiple CPUs.
Yet, to foster predictable scalability, each cluster can use at most three servers, each with at most eight CPUs, thus giving a total of twenty four CPUs for a single cluster.
Because each server with one CPU can, depending on message size, handle hundreds or thousands of requests per second, a single cluster will be able to handle dozens of thousands of requests per second or more. If needed, more clusters can be added to the same environment.
Recall that servers are always members of a cluster and that clusters are lightweight and cheap to create. It is typical to have more than one cluster for both scalability as well as HA, e.g. spread geographically across a continent with a CDN load-balancer in front of them directing external traffic to the nearest one.
