This article introduces features built into Zato that let one take advantage of publish/subscribe topics and message queues in communication between Zato services, API clients and backend systems.
Let's start by recalling the basic means through which services can invoke each other.
self.invoke will invoke another service directly, in a blocking manner, with the calling service waiting for a response from the target one.self.invoke_async, the calling service will invoke another one in background, without waiting for a response from the one being called.There are other variants too, like async patterns, and all of them work great but what they all have in common is that the entire communication between services takes place in RAM. In other words, as long as Zato servers are up and running, services will be able to communicate.
What happens, though, when a service invokes another one and the server the other one is running on is abruptly stopped? The answer is that, without publish/subscribe, a given request will be lost irrevocably - after all, it was in RAM only so there is no way for it to be available across server restarts.
Sometimes this is desirable and sometimes it is not - publish/subscribe topics and message queues focus on scenarios of the latter kind. Let's discuss publish/subscribe, then.
In its essence, publish/subscribe is about building message-based workflows and processes revolving around asynchronous communication.
Publishers send messages to topics, subscribers have queues for data from topics and Zato ensures that messages will be delivered to subscribers even if servers are not running or if subscribers are not currently available.
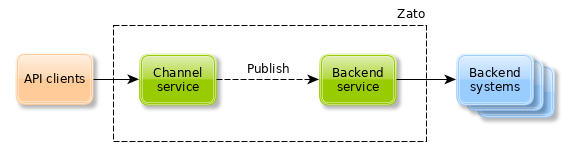
Publish/subscribe, as it pertains to Zato services, is an extension of the idea of message topics and queues. In this case, it is either internal or user-defined services that topics and queues are used by. Whereas previously, publishers and subscribers were external applications, here both of these roles are fulfilled by services running in Zato servers.
In the diagram above, an external API client invokes a channel service, for instance a REST one. Now, instead of using self.invoke or self.invoke_async the channel service will use self.pubsub.publish to publish the message received to a backend service which will in turn deliver it to external, backend systems.
The nice part of it is that, given how Zato publish/subscribe works, even if all servers are stopped and even if some of the recipients are not available, the message will be delivered eventually. That is the cornerstone of the design - if everything works smoothly, the message will be delivered immediately, but if anything goes wrong along the way, the message is retained and attempts are made periodically to deliver it to its destination.
As usual in Zato, the Python code needed is straightforward. Below, one service publishes a message to another - the programmer does not need to think about the inner details of publish/subscribe, about locations of servers, re-deliveries or guaranteed delivery. Merely using self.publish.publish suffices for everything to work out of the box.
# -*- coding: utf-8 -*-
from __future__ import absolute_import, division, print_function, unicode_literals
# Zato
from zato.server.service import Service
# ################################################################################
class MyService(Service):
name = 'pub.sub.source.1'
def handle(self):
# What service to publish the message to
target = 'pub.sub.target.1'
# Data to invoke the service with, here, we are just taking as-is
# what we were given on input.
data = self.request.raw_request
# An optional correlation ID to assign to the published message,
# if givenm it can be anything as long as it is unique.
cid = self.cid
self.pubsub.publish(target, data=data, cid=cid)
# Return the correlation ID to our caller
self.response.payload = cid
# ################################################################################
class PubSubTarget(Service):
name = 'pub.sub.target.1'
def handle(self):
# This is how the incoming message can be accessed
msg = self.request.raw_request
# Now, the message can be processed accordingly
# The actual code is skipped here - it will depend
# on one's particular needs.
# ################################################################################
The kind of message flows that publish/subscribe topics promote are called asynchronous because, seeing as in a general case it is not possible to guarantee that communication will be instantaneous, the initial callers (e.g. API clients) and possibly other participants too should only submit their requests without expectations that responses, if any, will appear immediately.
Consider a simple case of topping up a pay-as-you go mobile phone. Such a process will invariably require participation from at least several backend systems, all of which can be coordinated by Zato.
Let's say that the initial caller, the API client initiating the process, is a cell phone itself, sending a text message with a top-up code from a gift card.
Clearly, there is no need for the phone itself to actively wait for the response. With several backend systems involved, it may take anything between seconds to minutes before the card is actually recharged and there is no need to keep all of the systems involved, including the cell phone, occupied.
At the same time, in case some of the backend systems are down and the initial request is lost, we cannot expect that the end user will keep purchasing more cards - we need some kind of a guaranteed delivery mechanism, which is precisely where Zato topics are useful with their ability to retain messages in case immediate delivery is not possible.
With topics, if a response is needed, instead of waiting in a synchronous manner, API callers can be given a correlation ID (CID) on output when they submit a request. A CID is just a random piece of string, uniquely identifying the request.
In the Python code example, self.cid is used for the CID. It is convenient to use it because it already available for each service and Zato knows how to use it in other parts of the platform - for instance, if the request is via HTTP (REST or SOAP), the correlation ID will be saved in Apache-style HTTP access logs. This facilitates answering of typical support questions, such as 'What happened to this or that message, when was it processed or when was the response produced?'
We have a CID but why is it useful? It is because it may be used an ID to key messages of two kinds:
API callers may save it and then be notified later on by Zato-based services that such and such request, one with a particular CID, has been already processed
API callers may save it and then periodically query Zato-based services if a given request is already processed
Which style to use ultimately depends on the overall business and technical processes that Zato publish/subscribe and services support - sometimes it is more desirable to receive notifications yet sometimes it is not possible at all, e.g. if the recipients are rarely accessible, for instance, if they join networks irregularly.
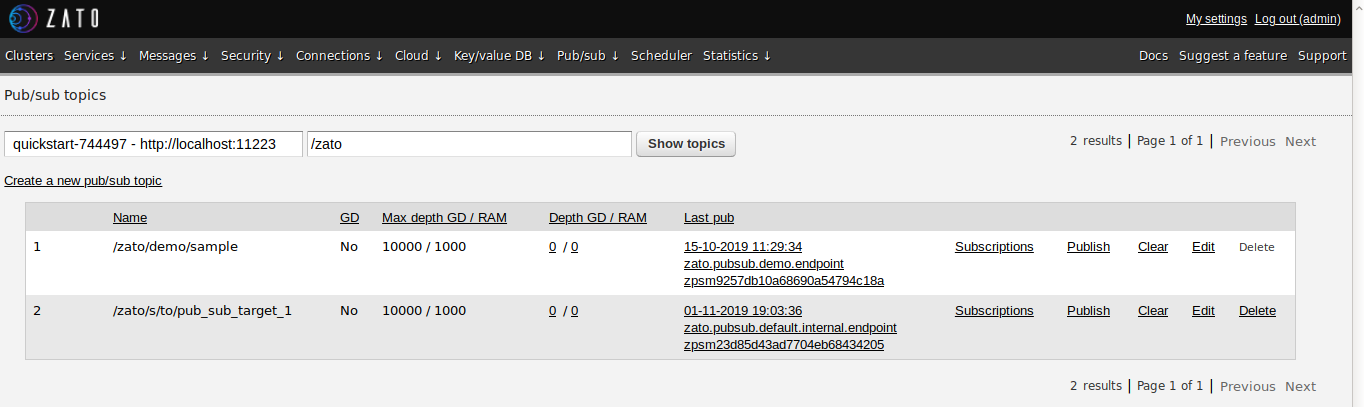
In parting words, it needs to be mentioned that a very convenient aspect of Zato services' being part of the bigger publish/subscribe mechanism is that web-admin GUI treats them just like any other endpoint and we can browse their topics, inspect last messages published, consult web-admin to check how many messages were published, or carry out other tasks that it is capable of, like in the screenshots below: