This blog post introduces the Zato scheduler - a feature of the platform that lets you configure API services and background jobs to be run at selected intervals and according to specified execution plans without any programming needed.
Future posts will introduce all the details whereas this one gently describes major features - overall architecture, one-time jobs, interval-based jobs, cron-style jobs and public API to manage jobs from custom tools.
In Zato, scheduler jobs are one of channels that a service can be invoked from - that is, the same service can be mounted on a REST, SOAP, AMQP, ZeroMQ or any other channel in addition to being triggered from the scheduler. No changes in code are required to achieve it.
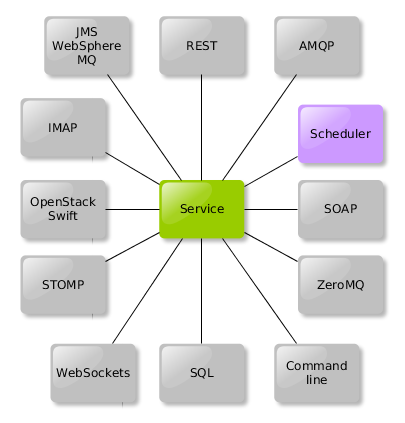
For instance, let's consider the code below of a hypothetical service that downloads billings from an FTP resource and sends them off to a REST endpoint:
from zato.server.service import Service
class BillingHandler(Service):
def handle(self):
# Download data ..
ftp = self.outgoing.ftp.get('Billings')
contents = ftp.getcontents('/data/current.csv')
# .. and send it to its recipient.
self.outgoing.plain_http['ERP'].post(self.cid, contents)
Nowhere in the service is any reference embedded as to how it will be invoked and this is the crucial part of Zato design - services only focus on doing their jobs not on how to make themselves available from one channel or another.
Thus, even if a service to bulk transfer billings initially will likely be invoked from the scheduler only, there is nothing preventing it from being triggered by a REST call or from command line as needed.
Or perhaps a message sent to an AMQP should trigger it - that is fine as well and the service will not need be changed to accommodate it.
There are three types of scheduler jobs:
00 3-6 * * 1-5 will mean 'run the service each full hour from 3am to 6am but only Monday to Friday (i.e. excluding weekends)'Note that job definitions always survive cluster restarts - this means that if you fully shut down a whole cluster of Zato servers then all jobs will continue to execute once the server is back. However, any jobs missed during the downtime will not be re-scheduled.
When a job is being triggered, its target service can receive extra data that may be possibly needed for that service to perform its tasks - this data is completely opaque to Zato and can be in any format, JSON, XML, YAML, plain text, anything.
If a job should not be scheduled anymore - be it because it was a one-time job or because it reached its execution limit, it becomes inactive rather than being deleted.
Such an inactive job still is available in the Zato Dashboard and can be made active again, possibly with a different schedule plan. On the other hand, actually deleting a job deletes it permanently.
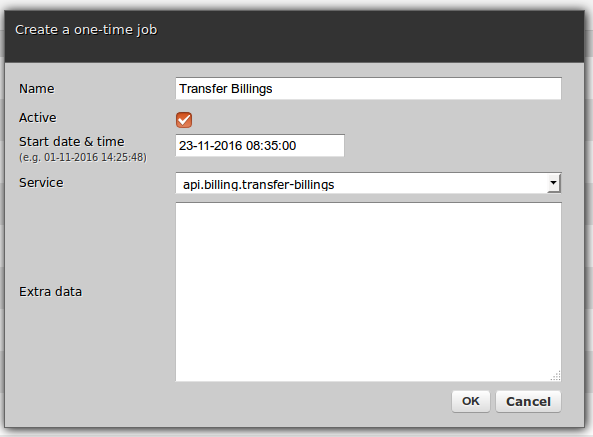
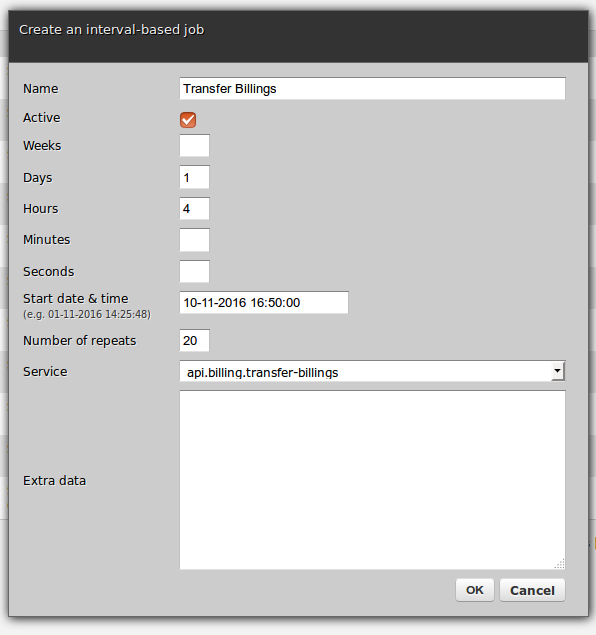
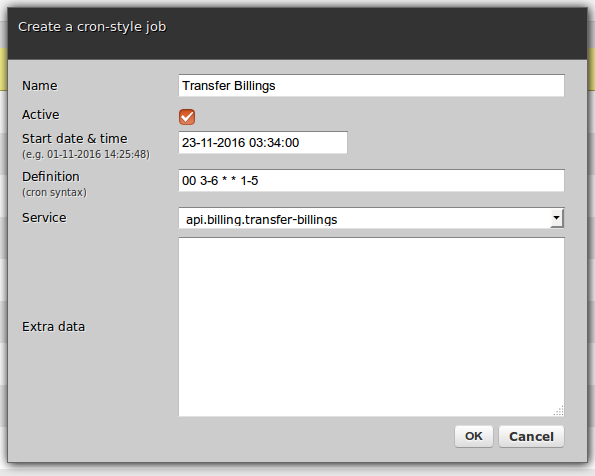
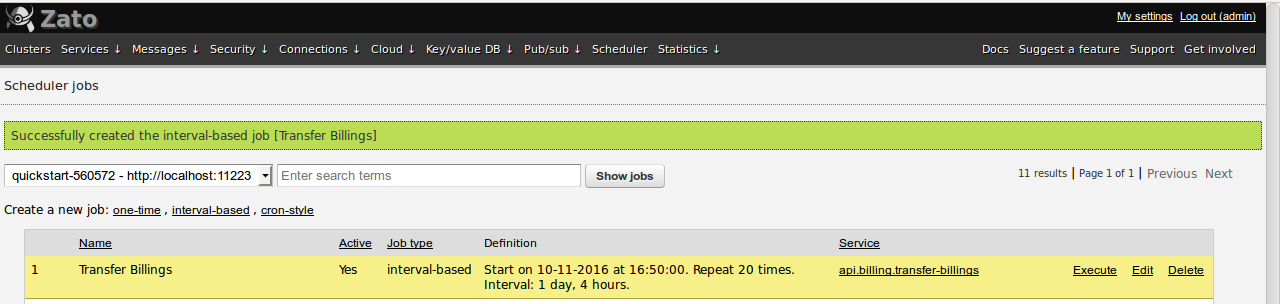
Full public API is available to manage jobs either through REST or SOAP calls as well as from other services directly in Python, such as below:
from zato.common import SCHEDULER
class JobManager(Service):
def handle(self):
# Create a sample job that will trigger one of built-in test services
self.invoke('zato.scheduler.job.create', {
'cluster_id': self.server.cluster_id,
'is_active': True,
'name': 'My Sample',
'service': 'zato.helpers.input-logger',
'job_type': SCHEDULER.JOB_TYPE.INTERVAL_BASED,
'seconds': 2,
})
This was just the first installment that introduced core concepts behind the Zato scheduler - coming up are details of how to work with each kind of the jobs, their API and how to efficiently manage their definitions in source code repositories.
