Quickstart clusters
The basics
A quickstart cluster is one that has all the Zato components installed in one system, under Docker, Vagrant or directly under Linux, using a special command called zato quickstart.
It is the zato quickstart command that sets up and configures a working cluster - for instance, even if you use Docker Quickstart, under the hood, it is this core command that automatically prepares a Zato environment even if outwardly you may not be invoking it directly.
Quickstart clusters are one of the two conceptual architectures for production environments, the other one are distributed clusters.
When to use quickstart clusters
Use quickstart if you would like to have a working environment spawned in a few seconds or minutes. It should be your first choice unless you have specific needs that preclude the usage of quickstart environments.
Such an environment is a real one in the sense that it uses all the components that Zato consists of and offers all the features that distributed environments do, but, instead of configuring everything manually, you let Zato auto-configure your installation.
One major difference between quickstart and distributed environments is that all components of a quickstart one run in the same operating system, container or VM, whereas the distributed one can be spread across multiple Linux instances.
The fact that there is one host server for the whole cluster has its implications regarding high availability (HA) and this is what most of the sections below are about.
Note that, even if there is one host server, the cluster can still use multiple Zato servers inside it. That is, a quickstart cluster may use multiple Zato servers to handle increased load, but they will all run inside the same host.
Also, in most cases, it is possible to achieve full HA by running multiple quickstart clusters in parallel. Read below for details.
A quickstart cluster with one server
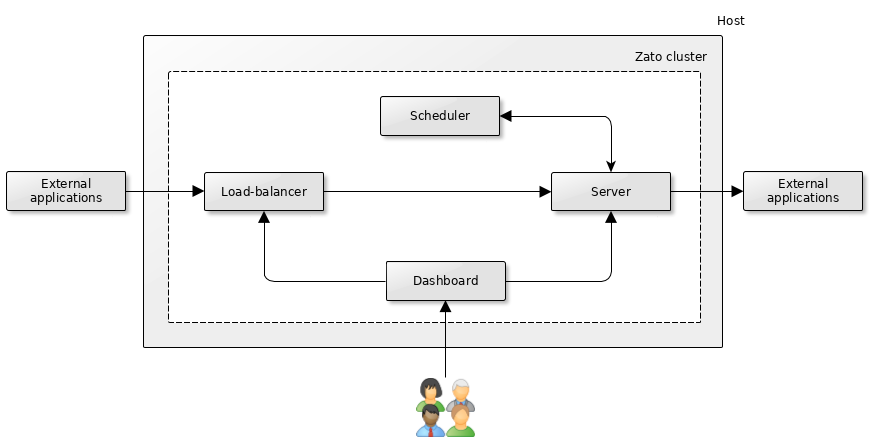
A single quickstart cluster with one server is a canonical unit of production deployment - all other approaches should be understood, discussed and reflected upon in comparison with what a cluster of this kind offers.
External applications invoke the cluster's built-in load-balancer which knows to what servers direct the traffic. In this particular case, there is only one server but, nevertheless, the load-balancer is used. If there is any need for public TLS certificates, they are configured on the load-balancer, not server. Similarly, any traffic shaping procedures find home on the load-balancer and prior to the server's receiving a request. An external load-balancer can be used instead of the built-in one, more about it later in the chapter.
The server offers API services and invokes external applications, as needed in a given project or integration.
The cluster's scheduler runs in background and periodically triggers its configured jobs which in turn invoke services from the server. Conversely, the server may need to access the scheduler too, e.g. to change its configuration.
The web-based Dashboard is used by developers and admins to manage the environment in runtime. Note that it runs as its own component - in particular, it means that you can open TCP traffic separately to the load-balancer and the dashboard, the latter being accessible only to specific IP addresses.
There is never any need for external applications to access the scheduler directly. The dashboard does not access the scheduler directly either, rather, it invokes the server which communicates with the scheduler on Dashboard's behalf.
All of these components are separate processes in the operating system and each of them can be started and stopped separately using zato start and zato stop commands.
Clusters of this sort have full access to all the capabilities that Zato offers, be it REST, batch processing, publish/subscribe, everything is available. One aspect to consider is HA - both in terms of being able to handle increasing load as well as avoiding downtime when the only server in the cluster becomes unavailable for any reason.
Note that it does not matter at all in what way such a cluster is created - the recommended means is Docker Quickstart but many other DevOps or Infrastructure as Code tools can be used. For instance, you can pre-build Packer images and deploy them with Ansible. Or you can set a Linux host in advance using Terraform and then run a custom Bash script to start a quickstart cluster. All kinds of provisioning tools can be used, be they cloud-native or not.
A quickstart cluster with N servers
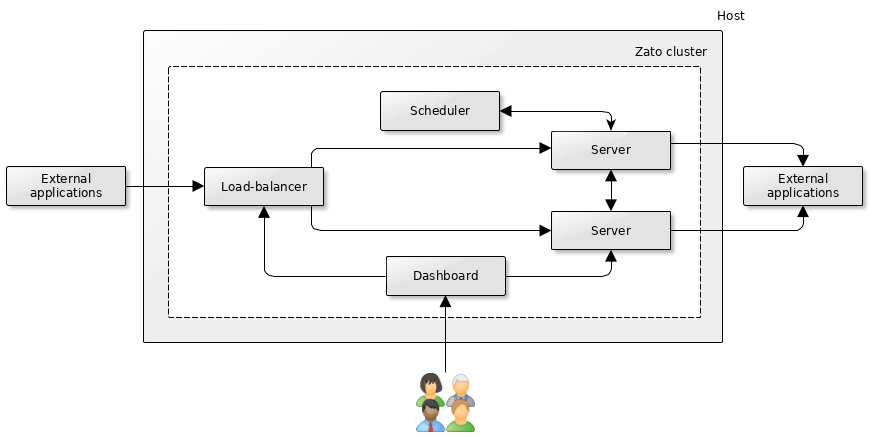
With more than one server running in a quickstart cluster, a degree of HA is achieved because, should one of the servers become inaccessible, the remaining one(s) can still process incoming requests.
In this setup, it is still possible for the whole environment to become unavailable should the entire host system go down. Multiple hosts with multiple quickstart clusters and an external load-balancer can be used to counter that, as it is discussed below.
External load-balancers
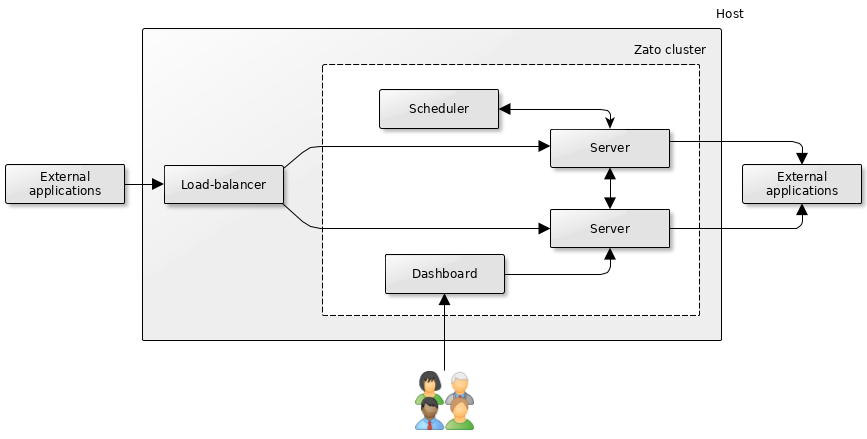
- In the diagram above, a load-balancer other than that the one built into Zato runs in front of servers. This may be desirable if you already have experience with or preferences towards specific load-balancing software. Zato servers will not be aware of this fact although Dashboard will not be able to manage such a load-balancer itself.
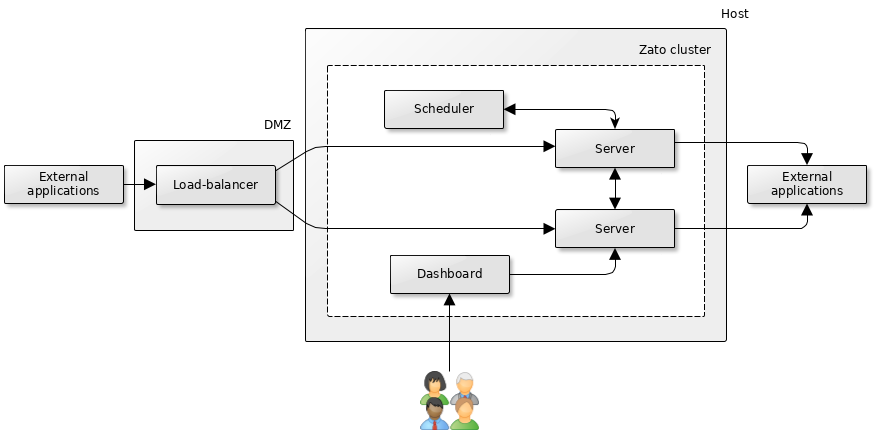
In the diagram above, the load-balancer is completely separate from both the Zato cluster and the host when the cluster runs.
The load-balancer can be a dedicated appliance or it can be software running in a bastion-like server, possibly in a locked down networking area, typically known as a DMZ. Alternatively, it can be a cloud-based load-balancer, e.g. ALB in AWS.
Multiple quickstart clusters with an external load-balancer
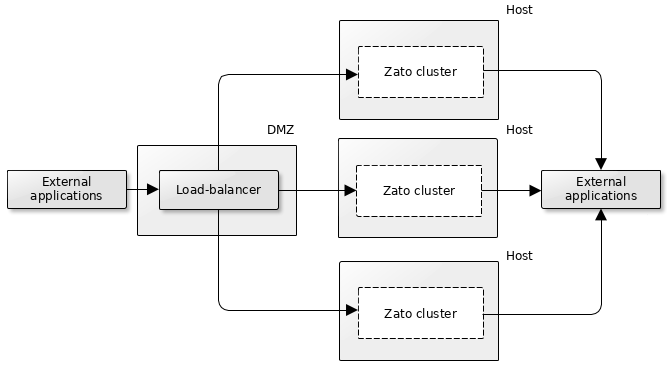
In this variant, there are multiple, identical Zato clusters and an external load-balancer directs traffic to each them. How the load-balancer works is up to you decide, e.g. it may be invoking each cluster in a round-robin fashion or it may invoke only one cluster and switch to a different one when the first one does not reply. Likewise, the clusters may be distributed geographically, for instance, they may reside in different data centers (availability zones) or different continents. Again, such details depend on particular HA needs of a given project and environment.
Recall from the architecture chapter that all servers in a single cluster run the same services and that their configuration or runtime state are not automatically shared between clusters.
The implication of the above is that any kind of services or capabilities that are stateless are a good candidate for an HA environment composed of multiple quickstart clusters. In other words, this is a good architecture as long as you do not use stateful capabilities, which are publish/subscribe, scheduler and WebSockets. If you use REST, SQL, MongoDB, Redis and other stateless features, quickstart HA clusters with an external load-balancer are a good choice.
The reason why the distinction between stateless vs. stateful features is made can be best explained through examples that will assume that you have an environment composed of two quickstart clusters.
Starting with REST, channels of this type are completely stateless, a request to REST-based service is made, the request is handled and there is no long-term data stored anywhere about this request that would let a subsequent request reference the current one. In this scenario, it does not matter which of the clusters, and which of the servers in each cluster, a REST connection will reach - each REST call is a separate being and they do not have any long-term state, hence stateless.
On the other hand, consider services triggered from a cluster's scheduler. For instance, if you would like for a specific service to be invoked once a minute, you need to take into account the fact that each cluster has its own scheduler. Because the clusters - and their schedulers - are not aware of each other, by default all schedulers in the environment will try to invoke the same service once a minute which is not as desired. Scenarios of this sort can be managed - for instance, in this case, it is always possible to start only one scheduler in a specific cluster and have your monitoring infrastructure probe that cluster's ping endpoints to trigger a failover to another scheduler should this one become unavailable, but this is something to take into account when designing for HA in advance.
How to create quickstart clusters
The recommended way to create production quickstart clusters is to use Docker Quickstart. This is a pre-built image that can be part of any of the architectures presented in this chapter. It is always up to date and contains various extra features that are often needed when building production environments.
If you need more control over how quickstart clusters are created, e.g. using Docker is not an option, you can invoke zato quickstart yourself in your own automation scripts and procedures. Ultimately, no matter which method you use, it is always this command that creates quickstart clusters.
Note that Zato environments can be built with any DevOps, automation and provisioning tools that you would like to use - you can embed the Docker Quickstart image in any containerization platform or, if you use zato quickstart directly, you can built images and provision instances in any preferred way, all the way from custom purpose-built scripts for one VM, through semi-automatic deployments up to highly dynamic zero-trust networks with components spawned on the fly when needed.
Learn more
Schedule a meaningful demo
Book a demo with an expert who will help you build meaningful systems that match your ambitions
"For me, Zato Source is the only technology partner to help with operational improvements."
 — John Adams
— John Adams
Program Manager of Channel Enablement at Keysight ![]()