Zato is an open-source, Python-based, API-led integration middleware and backend platform designed for integrations, automation, orchestration, interoperability, and the building of API-first, server-side systems.
Terms like an integration platform, IPaaS, enterprise service bus, API server, automation engine, service-oriented platform, interoperability engine, robotic process automation (RPA) platform, process mining platform, or integration layer, are commonly used to describe the product.
Zato is specifically designed with Python-based systems automation, integrations and backend, API-led solutions in mind.
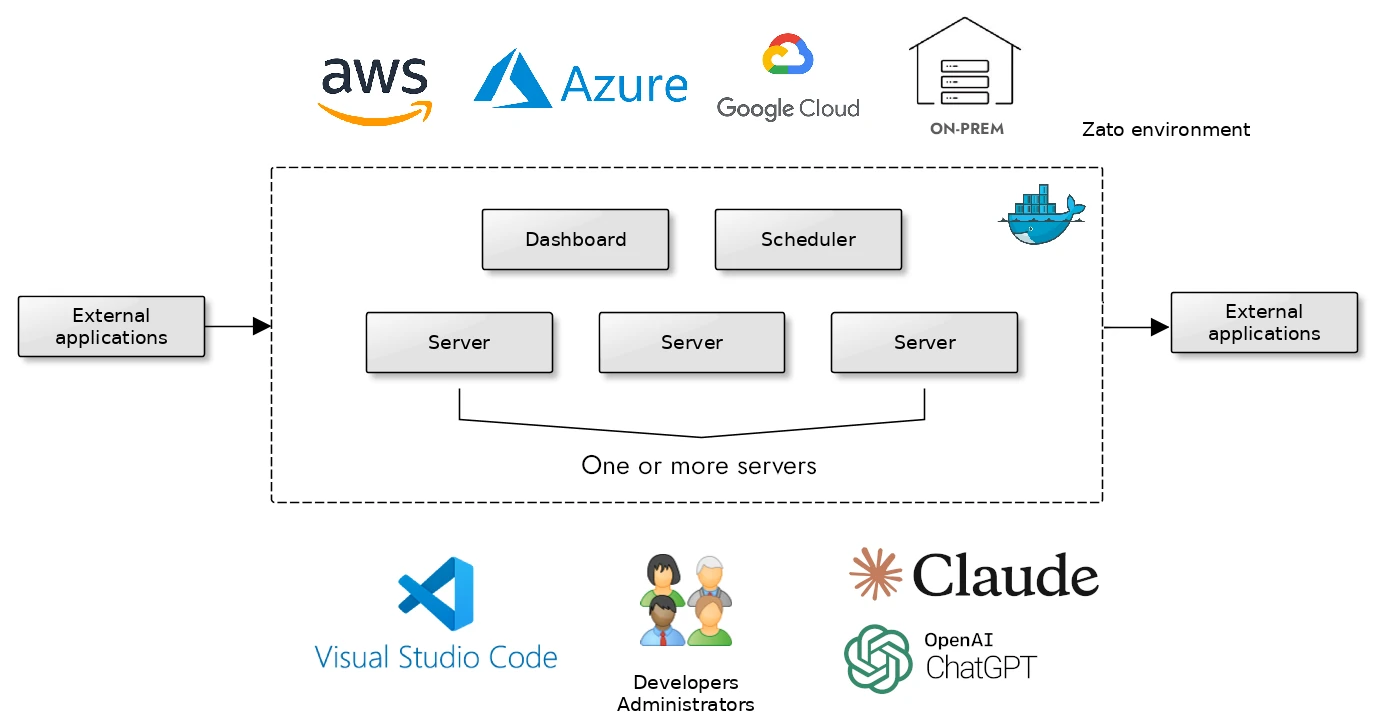
Each Zato environment is composed of one or more servers, each running in its own Docker Quickstart container, either in the cloud or on-prem. The environments can run in an active/standby or active/active mode.
You can connect your AI copilot or LLM to help you design and build your environments and integrations.
You can use a load-balancer in front of your servers. Most of the mainstream ones will work well, e.g. HAProxy, Envoy, NetScaler or AWS ELB.
Each server will have its Dashboard, and each environment will have a scheduler for scheduled jobs and tasks that run in the background.
A built-in Python IDE is available directly through each Dashboard, without a need to install additional apps on your computer. Simply install Zato, and you have everything that's needed for work.
Tight integration with the most popular IDEs is also provided out-of-the box, including deploy-on-save and remote debugging.
Hot-deployment is one of the fundamental concepts in Zato, particularly during development - when you deploy a new version of a service to a server, only that one service will be reconfigured and changed, there is no need to restart an entire server in such a case. Hot-deployment of new functionality is counted in milliseconds.
For DevOps and CI/CD pipelines, to ensure repeatable builds, you can export the entire configuration of your services to a YAML file that can be stored and versioned in git, and a container will import its contents when it's starting.
Monitoring of Zato servers can be enabled via out-of-the-box integrations with Datadog and Grafana Cloud
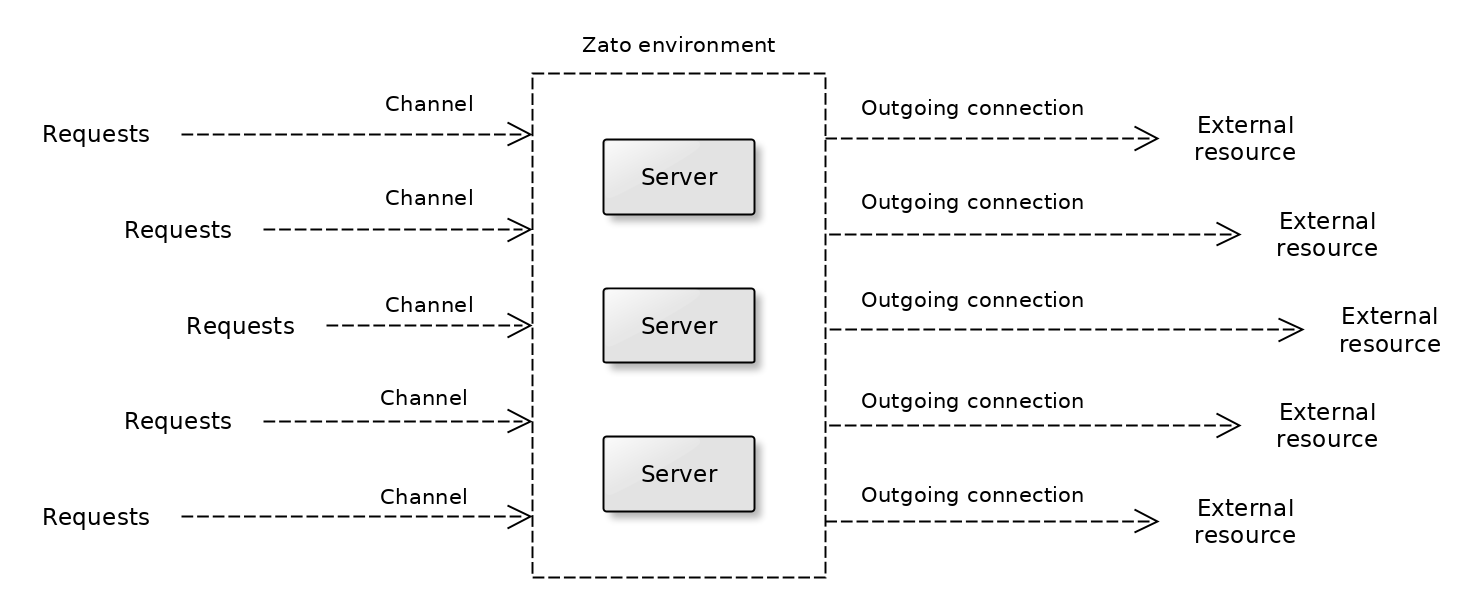
Servers in each cluster always execute the same code, no matter if your environment is an active/active or an active/standby one.
Requests are accepted by channels and external resources are accessed through outgoing connections.
Servers don't need to be able to communicate directly, which means they don't need direct TCP communication paths between each other. This makes it possible to have servers in different regions or data centers, e.g. one in US East, another in US Central, with a load-balancer in front of them.
Each server executes business services written in Python - to learn more about what a Zato service is, read the high-level overview.
Services can be independent of a particular data format of channel, e.g. the same service can use REST, JSON-RPC, File transfer, WebSockets, IBM MQ, AMQP or other communication means.
Services require little RAM in runtime and little time to deploy. A typical service will consume roughly 1 MB of RAM when idle and will require less than 1 ms to deploy. Hence, even a server with 500 or 1000 services will require little computing resources to operate, implying low electricity and cooling costs as well as low CO2 emission and environmental impact.
Services can accept requests through a range of channels. They can invoke other systems through one of many outgoing connection types, such as REST, AMQP, Microsoft 365 or other cloud services, HL7, SQL, MongoDB and various others typically used in backend environments.
Each server acts as a cache with a Python API for your services. The contents of the cache is also accessible through the server's dashboard.
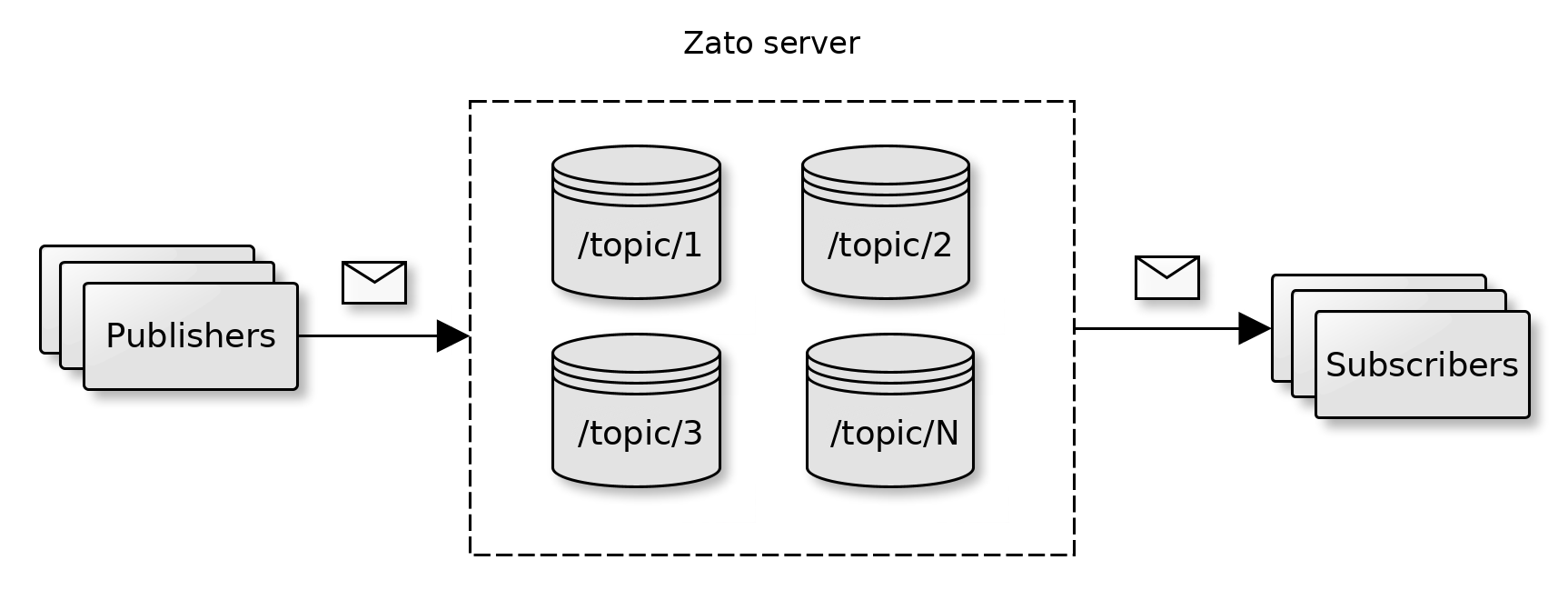
Each server can act as a publish/subscribe message broker offering topics and queues to asynchronous publishers and subscribers. Each server is an independent message broker and they don't share their queues with each other.
The message broker is multi-protocol and can be used by Python, REST, WebSockets or File transfer clients. Each cluster's Dashboard acts as a GUI to manage the topics, queues and endpoints participating in pub/sub integrations.
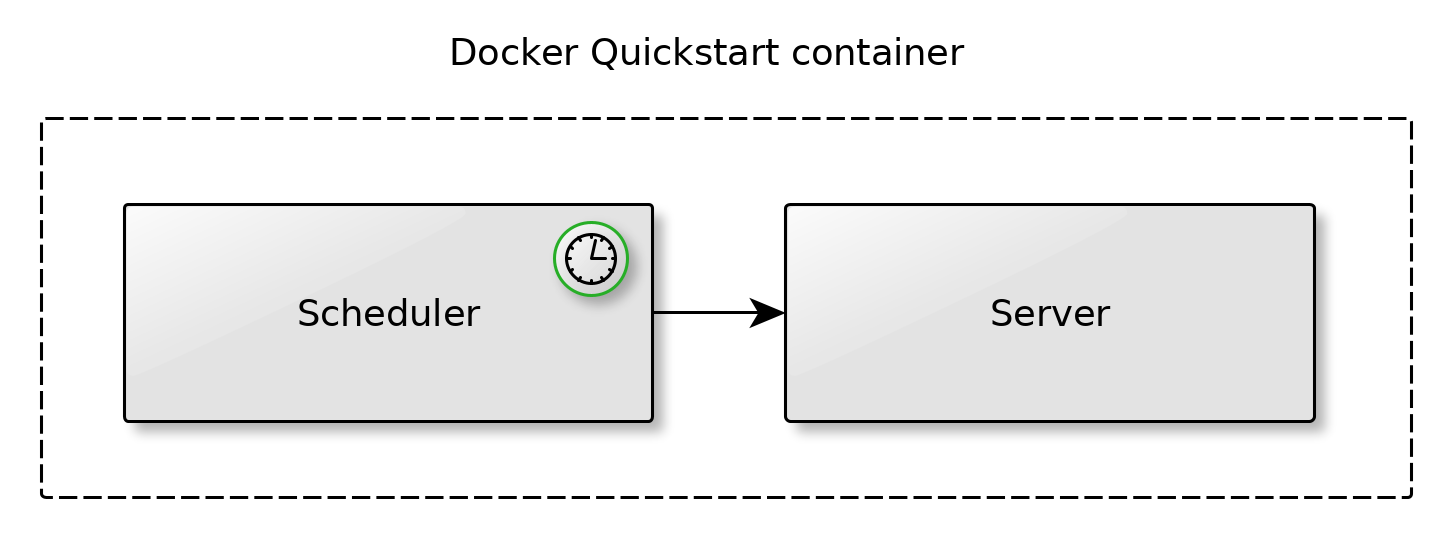
Each environment may use a highly configurable scheduler whose jobs can be triggered in predefined intervals.
Each job invokes a service on a server. Because services are protocol independent, it means that the same service can be made available to external API clients and, internally, to the scheduler as well.
It is possible for services to schedule jobs dynamically in runtime, for instance, in reaction to other events taking place in integration processes, e.g. picture a zero-trust network where access to resources is offered through automation that creates accounts on demand and then cleans everything up after N minutes.
Learn how to design environments with a specific goal in mind:
Book a demo with an expert who will help you build meaningful systems that match your ambitions
"For me, Zato Source is the only technology partner to help with operational improvements."
 — John Adams
— John Adams
Program Manager of Channel Enablement at Keysight ![]()