Book a demo with an expert who will help you build meaningful systems that match your ambitions
"For me, Zato Source is the only technology partner to help with operational improvements."
 — John Adams
— John Adams
Program Manager of Channel Enablement at Keysight ![]()
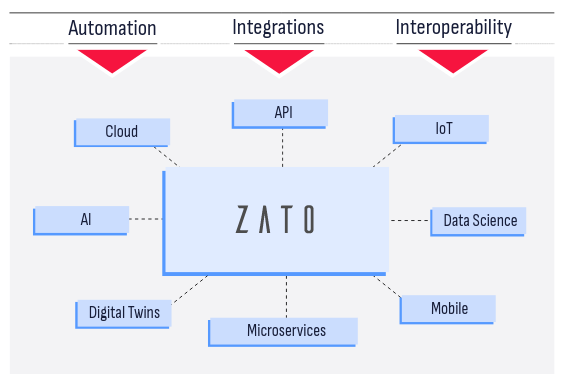
ESB, API, AI and Cloud Integrations in Python
Open-source total product with enterprise support
To book a demo, click here ➤
For professional services, click here ➤
Developer? Click to visit the documentation ➤
Solving complex challenges? Read case studies ➤